R tutorial series: Analyzing bacterial growth from OD600 data
Bacterial growth analysis is a fundamental task in microbiology, allowing researchers to monitor the proliferation of bacteria over time. Optical Density at 600 nm (OD600) is a commonly used method to measure this growth. In this tutorial, we’ll walk through the process of analyzing bacterial growth data using R: loading and tidying the data, visualizing growth curves for several samples at once, automatically detecting each sample’s exponential phase to estimate its maximum specific growth rate (μmax), and comparing growth rates across samples. This is just basic things for a new undergrad biology student and a nice way to start learning microbiology.
Libraries we need
We start by defining the libraries that will be used in our analysis.
libs <- c(
"readr", "dplyr", "tidyr", "purrr", "lubridate",
"ggplot2", "ggsci", "plotly", "knitr")
installed_libs <- libs %in% rownames(installed.packages())
if (any(installed_libs == FALSE)) {
install.packages(libs[!installed_libs])
}
invisible(lapply(libs, library, character.only = TRUE))readr for reading the CSV, dplyr/tidyr/purrr for wrangling, lubridate for parsing the time stamps, ggplot2/ggsci for static plots, plotly for an interactive version, and knitr for printing tidy summary tables.
Load and tidy the data
We load the OD600 data from a CSV file (Excel works too, just keep the same column layout). You can download example data here. This is personal data collected during my training at the University of Vienna, using Vibrio as a bacterial model grown in marine broth liquid medium.
The raw file has one row per reading, with a Sample_name column encoding both the sample and the time it was taken (e.g. WT_09:15), plus the raw Result (OD600 reading). The workflow below supports any number of samples — nothing has to change if you add more.
blank_od <- 0.001 # OD600 of your blank/media-only well — adjust to your own measurement
df <- read_csv("od_data2.csv") %>%
mutate(
Sample = sub("_.*", "", Sample_name),
Time = sub(".*_", "", Sample_name),
Time = hm(Time),
Result = Result - blank_od) %>%
filter(Result > 0) %>% # can't take log() of a non-positive OD
mutate(Result_log = log(Result)) %>%
group_by(Sample) %>%
arrange(Time, .by_group = TRUE) %>%
mutate(Time_h = as.numeric(Time - min(Time), units = "hours")) %>%
ungroup() %>%
select(Sample, Time_h, Result, Result_log)
glimpse(df)## Rows: 34
## Columns: 4
## $ Sample <chr> "t1.1", "t1.1", "t1.1", "t1.1", "t1.1", "t1.1", "t1.1", "t1…
## $ Time_h <dbl> 12.51667, 13.70000, 13.96667, 14.23333, 14.45000, 14.73333,…
## $ Result <dbl> 0.001, 0.005, 0.008, 0.014, 0.019, 0.032, 0.049, 0.078, 0.0…
## $ Result_log <dbl> -6.907755, -5.298317, -4.828314, -4.268698, -3.963316, -3.4…A few changes from a “just read the CSV” approach worth calling out:
- The blank correction lives in a named
blank_odvariable instead of a magic number buried in a pipe, so it’s obvious what to change for your own plate reader. - Any blank-corrected reading
<= 0is dropped before log-transforming — otherwiselog()silently returns-Inf/NaNand breaks the regressions further down. Timeis converted to hours elapsed since that sample’s first reading (Time_h), computed per sample. That keeps the x-axis in intuitive units and means samples that were started at different clock times still line up at t = 0.
Growth curves for all samples
With tidy data in hand, we can plot every sample’s growth curve on one panel.
p_raw <- ggplot(df, aes(x = Time_h, y = Result, color = Sample)) +
geom_line() +
geom_point(size = 1) +
labs(
title = "Optical Density λ600",
x = "Time (hours)",
y = "Optical Density (OD600)") +
scale_color_nejm() +
theme_minimal()
p_raw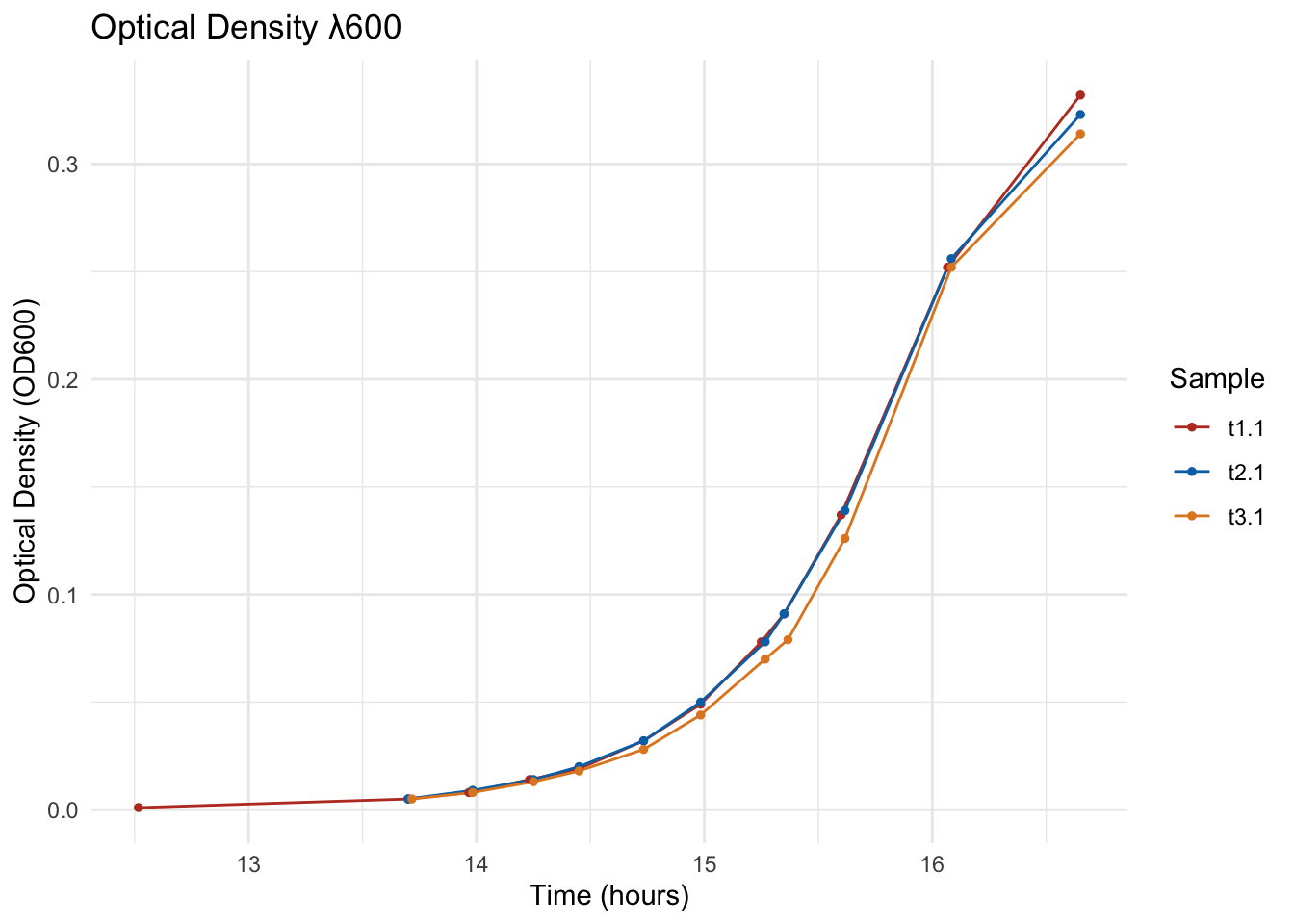
Log-transformed OD600
Plotting log(OD600) against time is what makes the exponential phase visible as a straight line — that straight segment is exactly what the next section detects automatically.
p_log <- ggplot(df, aes(x = Time_h, y = Result_log, color = Sample)) +
geom_line() +
geom_point(size = 1) +
labs(
title = "Optical Density λ600 (log scale)",
x = "Time (hours)",
y = "log(Optical Density)") +
scale_color_nejm() +
theme_minimal()
p_log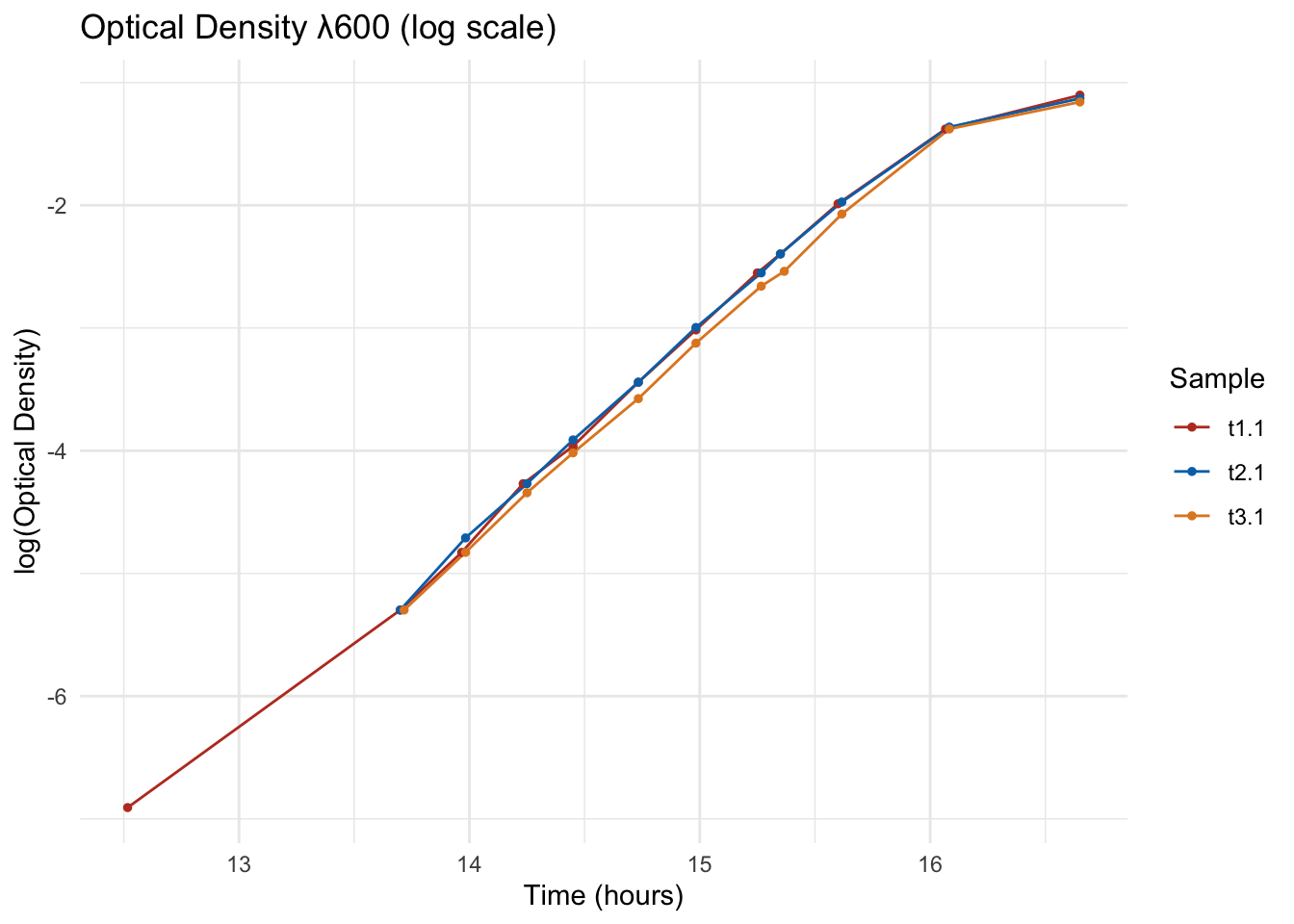
Finding μmax with a sliding-window regression
In batch culture, growth during the exponential phase follows
\[ \frac{dN}{dt} = \mu N \]
so a straight line fit to log(N) vs. time has slope μ, the specific growth rate. μmax is the highest μ sustained anywhere in the curve — i.e. the steepest straight stretch of the log-transformed curve.
Rather than eyeballing where the exponential phase starts and ends (as I did in an earlier version of this post, and which has to be re-guessed by hand for every new sample), we slide a small window of consecutive time points along each sample’s curve, fit a linear regression of Result_log ~ Time_h inside every window, and keep the window with the steepest good-quality fit. This is the same idea used by dedicated growth-curve tools like the growthcurver package.
find_mu_max <- function(data, window = 5) {
data <- arrange(data, Time_h)
n <- nrow(data)
if (n < window) {
return(tibble())
}
map_dfr(1:(n - window + 1), function(i) {
w <- data[i:(i + window - 1), ]
fit <- lm(Result_log ~ Time_h, data = w)
tibble(
window_start = min(w$Time_h),
window_end = max(w$Time_h),
mu = unname(coef(fit)[2]),
r_squared = summary(fit)$r.squared
)
})
}window is the number of consecutive readings used per regression — tune it to your sampling frequency (e.g. a smaller window for coarser sampling, a larger one for very frequent readings) so each window still spans a few minutes of real growth.
We apply this per sample, then for each sample keep the best window: the steepest slope among windows with a good linear fit (r_squared > 0.98).
growth_windows <- df %>%
group_by(Sample) %>%
group_modify(~ find_mu_max(.x, window = 5)) %>%
ungroup()
mu_max_summary <- growth_windows %>%
filter(r_squared > 0.98, mu > 0) %>%
group_by(Sample) %>%
slice_max(mu, n = 1, with_ties = FALSE) %>%
ungroup() %>%
mutate(doubling_time_min = (log(2) / mu) * 60) %>%
select(Sample, mu_max = mu, r_squared, window_start, window_end, doubling_time_min)
kable(mu_max_summary, digits = 3,
col.names = c("Sample", "μmax (h⁻¹)", "R²",
"Window start (h)", "Window end (h)", "Doubling time (min)"))| Sample | μmax (h⁻¹) | R² | Window start (h) | Window end (h) | Doubling time (min) |
|---|---|---|---|---|---|
| t1.1 | 1.797 | 0.998 | 13.700 | 14.733 | 23.140 |
| t2.1 | 1.782 | 0.998 | 13.700 | 14.733 | 23.332 |
| t3.1 | 1.703 | 0.999 | 13.717 | 14.733 | 24.420 |
The doubling time follows directly from μmax:
\[ t_d = \frac{\ln(2)}{\mu_{max}} \]
Checking the detected exponential phase
Before trusting these numbers, it’s worth visualizing which window was picked for each sample, overlaid on the log-transformed curve.
ggplot(df, aes(x = Time_h, y = Result_log)) +
geom_rect(
data = mu_max_summary,
aes(xmin = window_start, xmax = window_end, ymin = -Inf, ymax = Inf),
inherit.aes = FALSE, fill = "grey80", alpha = 0.5
) +
geom_line(aes(color = Sample), show.legend = FALSE) +
geom_point(aes(color = Sample), size = 1, show.legend = FALSE) +
facet_wrap(~Sample, scales = "free_x") +
labs(
title = "Detected exponential-phase window per sample",
x = "Time (hours)", y = "log(Optical Density)") +
scale_color_nejm() +
theme_minimal()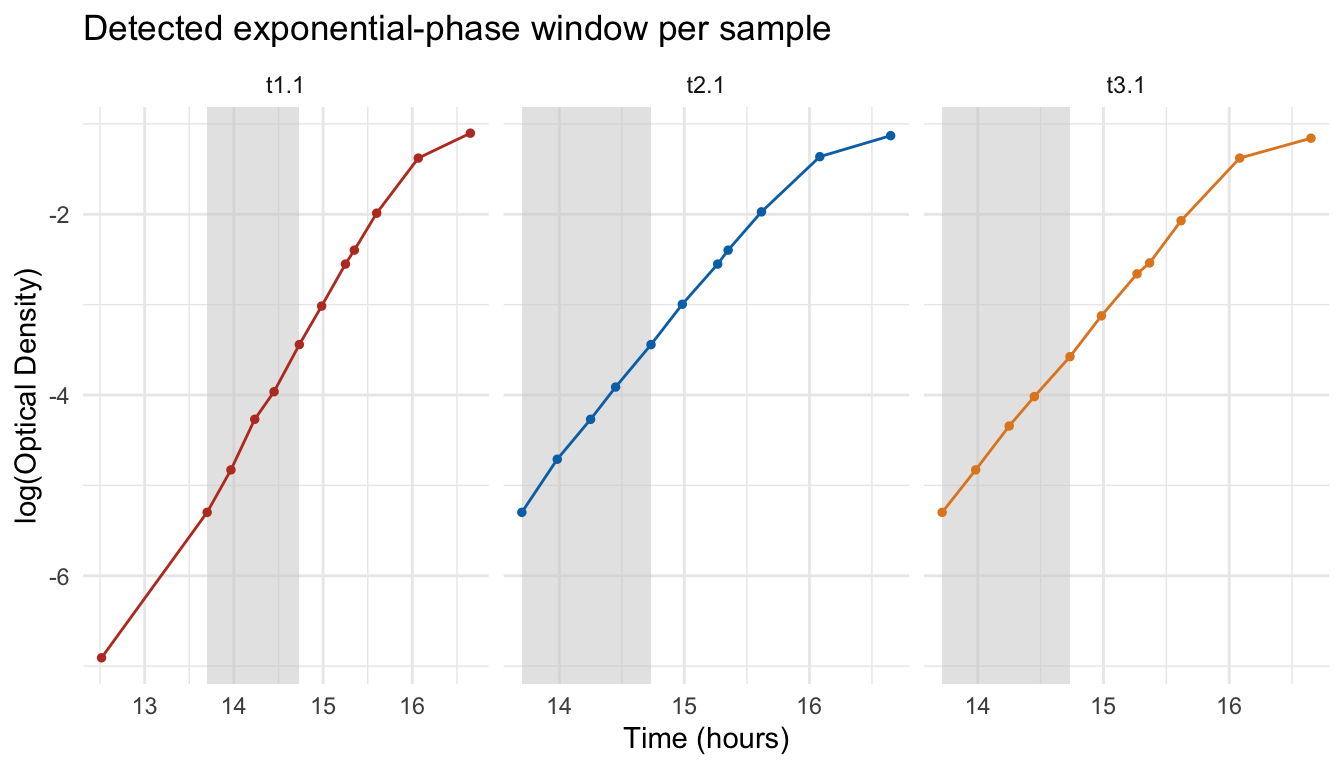
The shaded rectangle is the window find_mu_max() selected for that sample. If it looks too short, too noisy, or off to one side, adjust the window size or the r_squared cutoff above and re-run.
Comparing growth rate across samples
This is the part that’s easy to lose track of when analyzing one sample at a time: how do the samples actually compare?
mu_max_summary %>%
select(Sample, `μmax (h⁻¹)` = mu_max, `Doubling time (min)` = doubling_time_min) %>%
pivot_longer(-Sample, names_to = "metric", values_to = "value") %>%
ggplot(aes(x = reorder(Sample, value), y = value, fill = Sample)) +
geom_col(show.legend = FALSE) +
facet_wrap(~metric, scales = "free_x") +
coord_flip() +
scale_fill_nejm() +
labs(x = NULL, y = NULL, title = "Growth rate vs. doubling time by sample") +
theme_minimal()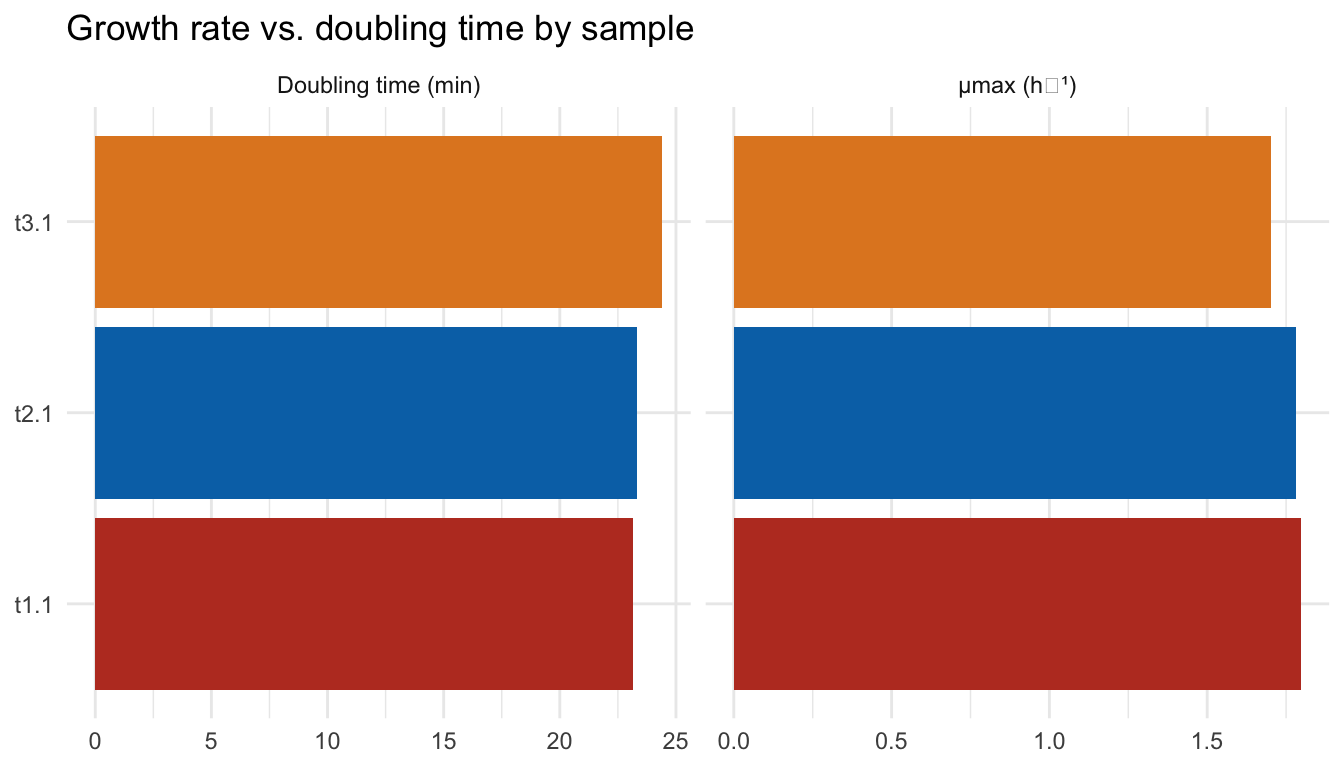
Interactive growth curve
Handy for zooming into a specific stretch of the curve or checking individual points.
ggplotly(p_raw)Remarks
By automating exponential-phase detection with a sliding-window regression, this workflow scales to any number of samples without hand-tuning a lag_end/exp_end cutoff for each one, and the μmax/doubling-time table and every plot above are regenerated straight from the raw CSV whenever this document is knitted. That makes the whole analysis reproducible: re-run it on a new plate and the numbers and figures update themselves.
Buy me a coffee See you in the next post and have a beautiful day!